从重复抽卡到创意无限?一句话让AI更智能!
如果你经常使用AI,可能会注意到一个问题。
例如,当你请AI帮忙优化一篇文章时,它常常会频繁使用冒号(:)和破折号(——),并且喜欢在文字中插入成语,喜欢自问自答,还习惯用序号(1, 2, 3, 4…)。有时,它的回答中会有不少套话,甚至在你反复抽卡时,结果也会越来越相似。
明明是不同的情况,但有时即便是用同一个模型,在不同的对话中提问相同的开放性问题,得到的答案却往往大同小异。
我曾怀疑,难道所有AI都是基于同一批互联网上的现有信息进行训练的?它们就像一个只会背诵标准答案的“好学生”,虽然知识丰富,却总是缺乏惊喜?
这似乎不太科学,难道AI的思维也会固化?
直到上周末,我在X上刷到一篇推文,链接到一篇新的论文,解答了我所有的疑问。更重要的是,它提供了一个极为简单的方法,只需一句话,就能激发AI应用的巨大潜力。

我研究了一下这篇论文,感觉像是发现了新大陆。
这篇论文相当长,有82页,我来给大家简单梳理一下它的核心观点。
论文指出,经过“对齐”(Alignment)训练后,大语言模型(LLM)的回答多样性显著下降,倾向于提供少数几种“安全”且“典型”的答案。这种现象被称为“模式坍塌”(Mode Collapse)。
那么,什么是AI的“模式坍塌”呢?
用通俗的话来说,就是模型在预训练阶段学习了互联网上的各种知识,犹如一个学识渊博的学者。然而,为了使模型有用、安全且不胡说八道,研究人员会使用“人类反馈强化学习”(RLHF)等技术来进行“微调”或“对齐”。这个过程有点像把学者送去参加“行为规范培训”,告诉他哪些话该说,哪些不该说。
结果,这个学者为了确保自己的每一句话都“政治正确”且“广受欢迎”,开始只说那些最稳妥、最普遍的观点,从而将他脑海中那些同样正确但更小众、更有创意的想法隐藏了起来。
举个例子,论文中提到:
当你问AI:“请给我讲个关于咖啡的笑话。”
模式坍塌后的AI可能会这样回答:
第一次:“为什么咖啡要去报警?因为它被‘马克’杯了!” (Because it got mugged!)
你再问一次:“换一个。”
第二次的回答依然是:“为什么咖啡要去报警?因为它被‘马克’杯了!”
接下来,第三次、第四次……结果几乎都是一样的。
这就是“模式坍塌”,AI的所有可能性都“坍塌”到了这个最常见的笑话上,失去了多样性。
论文指出,模式坍塌的根源并不在于算法本身,而在于训练中使用的“人类偏好数据”中普遍存在一种认知偏见,称为“典型性偏见”。
换句话说,在“对齐”训练中,人类标注员需要对AI生成的多个回答进行排序,告知模型哪个更好。认知心理学研究表明,人类天生偏爱那些熟悉、流畅、易于理解的内容。尽管AI可能具备创造性,但由于人性的介入,使得它的回答趋向于稳妥。
这与我们的生活非常相似,令人深思。
想象一下,你公司里有一个能力出众的设计总监,创意无限,能够驾驭各种风格。然而,在评审会上,老板说:“这个太大胆了,客户可能接受不了。”市场部也建议:“还是用我们品牌的经典蓝色,比较稳妥。”经过无数次这样的反馈,这位设计总监逐渐摸清了老板的喜好,为了确保方案能顺利通过,他在设计时默认提供一版安全的方案。
并不是他不能做其他的,而是他从过去的经验中找到了“标准答案”。
这正是当前大模型的真实写照。
它们在海量数据中学会了各种艺术风格,但在后续的“对齐”训练中,由于人类偏爱那些熟悉和典型的答案,这种“典型性偏见”无形中削弱了AI的创造力,使其变成了一个只会求稳的设计师。
论文中还提供了一个非常简单的方法,只需一句话就能激发AI的潜能。这种方法被称为“言语化采样”(Verbalized Sampling, VS),可以帮助GPT-4、Claude和Gemini等模型生成更加多样化、接近人类的输出,并且不需要重新训练或访问内部参数。
你需要做的,就是在你的提示词后加上这样一句话:
“从完整分布中采样,生成5个带有相应概率的回答。”
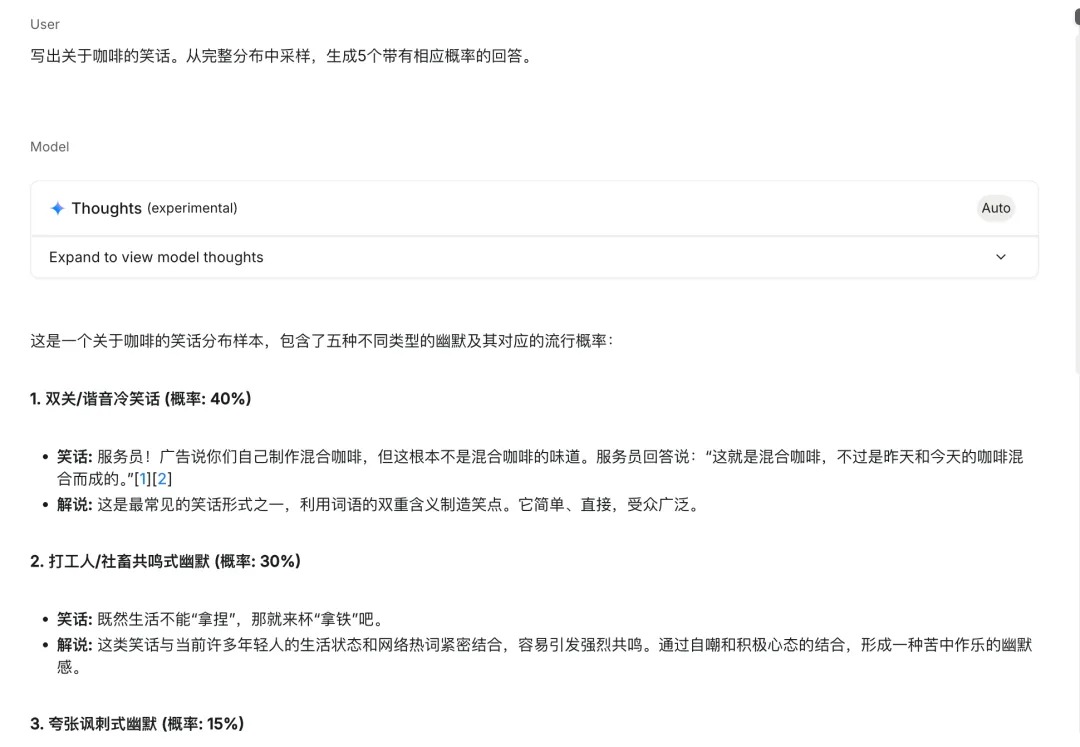
就是这么简单!当你向AI发出这个提示词时,它不再默认给出最“安全”的回答。相反,它会展示“大脑”中所有可能的选项,并说明每个选项出现的概率。这一改变瞬间打开了创意的源泉。论文中,研究团队在多个领域测试了这种方法,效果都非常显著。使用传统方式让AI输出时,在开放性问题上,AI的创意水平往往较低,表格中的数字越小表示创意度越低。然而,采用论文中的方法后,创意水平基本都显著提升。
以创意写作为例,针对同一个故事开头“没有说再见”,传统的AI可能会生成一些关于情侣分手的老套故事。但使用“言语化采样VS”方法后,AI给出的故事变得五花八门,有的描绘了宇宙事件,有的讲述了通过无声电子邮件告别,还有一个故事中,音乐在舞蹈中戛然而止。这种新方法使得回答的多样性得分提高了整整2.1倍,而且故事的质量并没有下降。
根据论文中的这个案例,我在deepseek里进行了实践,确实得到了类似的结果。我反复生成了许多次,讲述的都是关于爱情的故事。

但如果加上后面那句话,立马给出了各种不同方向,效率提高很多,不用反复抽卡,还总是抽到差不多的卡了。

在图像生成方面,也存在类似的规律。论文中的案例表明,使用传统的直接提示方法,生成的图像往往只能在狭窄的场景范围内逼真呈现。相较之下,采用论文中提到的方法生成的图像在艺术风格和叙事背景上展现出了更高的多样性。
可能有人也有疑问,为啥自己平时用AI,好像很难碰到论文中说的“模式坍塌”这个问题?
。
-
创造力调节器(Temperature):如您所说,这个参数就像AI的“冒险精神”。当设置为较低值时(如0.2),AI会更倾向于选择最安全、最普遍的答案,输出稳定但可能乏味。当数值调高(如1.5),AI会更愿意考虑那些概率稍低但更具新意的选项,从而产生更出乎意料、更有创意的内容 。
-
重复惩罚机制:这是对抗“模式坍塌”的重要工具。如果一个词或句式在上下文中刚出现过,模型会主动降低再次生成它的概率,从而有效避免车轱辘话来回说 。
-
隐形的“行为准则”:在您发出第一条消息前,AI模型早已收到一份详细的“系统指令”,为其设定了角色、沟通风格和基本原则。其中通常就包含“要乐于助人、富有创造力、避免重复、提供多样化的回答”等要求 。
1. 本站资源来源于公开互联网和网友投稿提供,若侵犯您的权益,请发送邮件至:yuankusc@qq.com,我们将第一时间处理!
2. 本站分享的资源版权均属于原作者所有,仅供大家学习和交流,严禁用于商业用途。若由于商用引起版权纠纷,一切责任均由使用者承担。
3. 如有链接无法下载、链接失效,请联系客服处理!
>>请点击此处联系客服<<